
Goで実装するNeo4jの読み取り専用MCPサーバー(SSE)
はじめに
このチュートリアルでは、Go言語を使ってNeo4jデータベースにアクセスできるMCPサーバーを書く方法をデモンストレーションします。実装が完了すると、クエリコードを一切書かずに、大規模言語モデルに問い合わせるだけでサーバーの状況を把握できるようになります。
従来の接続方法とは異なり、今回はSSE(Server-Sent Events)方式でサーバーの作成と接続を行います。
今回のチュートリアルのコード:https://github.com/LSTM-Kirigaya/openmcp-tutorial/tree/main/neo4j-go-server
このコードをダウンロードすることをお勧めします。なぜなら、私が準備したデータベースファイルが含まれているからです。そうでないと、自分でデータをモックする必要があります。
1. 準備
プロジェクトの構造は以下の通りです:
📦neo4j-go-server
┣ 📂util
┃ ┗ 📜util.go # ユーティリティ関数
┣ 📜main.go # メイン関数
┗ 📜neo4j.json # データベース接続のアカウント情報まずGoプロジェクトを作成します:
mkdir neo4j-go-server
cd neo4j-go-server
go mod init neo4j-go-server2. データベースの初期化を完了する
2.1 Neo4jのインストール
まず、私のチュートリアルに従ってローカルまたはサーバーにNeo4jデータベースを設定します。ここではチュートリアルですので、このチュートリアルの最初の2ステップだけを完了すれば十分です:Neo4jデータベースのインストールと設定。binパスを環境変数に追加し、パスワードをopenmcpに設定します。
次に、main.goと同じ階層にneo4j.jsonを作成し、Neo4jデータベースの接続情報を記入します:
{
"url" : "neo4j://localhost:7687",
"name" : "neo4j",
"password" : "openmcp"
}2.2 事前に準備されたデータのインポート
インストールが完了したら、私が事前に準備したデータをインポートできます。これらのデータは私の個人ウェブサイトの一部のデータを匿名化した要約です。自由に使用してください。ダウンロードリンク:neo4j.db。ダウンロードが完了したら、以下のコマンドを実行します:
neo4j stop
neo4j-admin load --database neo4j --from neo4j.db --force
neo4j startその後、データベースにログインすると、私が準備したデータを見ることができます:
cypher-shell -a localhost -u neo4j -p openmcp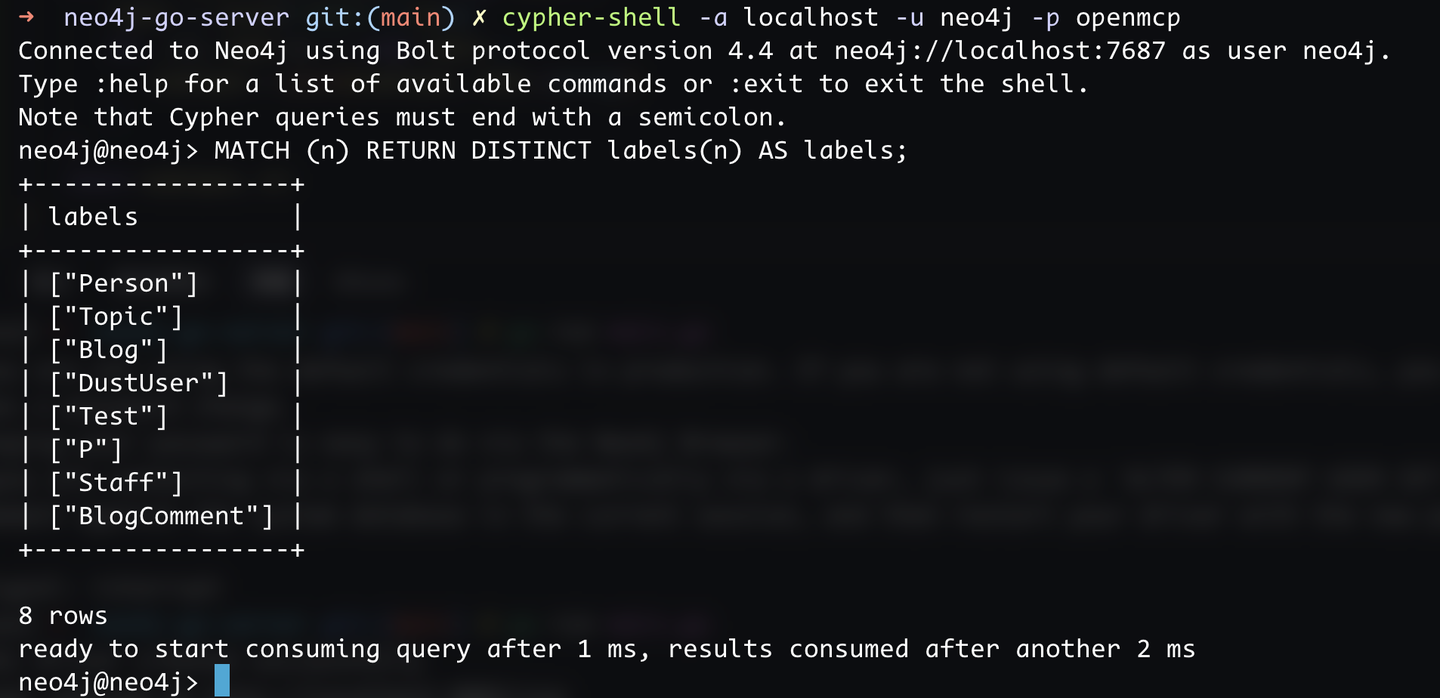
2.3 Goからデータベースへの接続性を検証する
データベースの接続性とGoのデータベースドライバーが正常に動作していることを確認するために、まずデータベースアクセスの最小システムを書く必要があります。
まず、Neo4jのv5バージョンのGoドライバーをインストールします:
go get github.com/neo4j/neo4j-go-driver/v5util.goに以下のコードを追加します:
package util
import (
"context"
"encoding/json"
"fmt"
"os"
"github.com/neo4j/neo4j-go-driver/v5/neo4j"
)
var (
Neo4jDriver neo4j.DriverWithContext
)
// Neo4jサーバーへの接続を作成
func CreateNeo4jDriver(configPath string) (neo4j.DriverWithContext, error) {
jsonString, _ := os.ReadFile(configPath)
config := make(map[string]string)
json.Unmarshal(jsonString, &config)
// fmt.Printf("url: %s\nname: %s\npassword: %s\n", config["url"], config["name"], config["password"])
var err error
Neo4jDriver, err = neo4j.NewDriverWithContext(
config["url"],
neo4j.BasicAuth(config["name"], config["password"], ""),
)
if err != nil {
return Neo4jDriver, err
}
return Neo4jDriver, nil
}
// 読み取り専用のCypherクエリを実行
func ExecuteReadOnlyCypherQuery(
cypher string,
) ([]map[string]any, error) {
session := Neo4jDriver.NewSession(context.TODO(), neo4j.SessionConfig{
AccessMode: neo4j.AccessModeRead,
})
defer session.Close(context.TODO())
result, err := session.Run(context.TODO(), cypher, nil)
if err != nil {
fmt.Println(err.Error())
return nil, err
}
var records []map[string]any
for result.Next(context.TODO()) {
records = append(records, result.Record().AsMap())
}
return records, nil
}main.goに以下のコードを追加します:
package main
import (
"fmt"
"neo4j-go-server/util"
)
var (
neo4jPath string = "./neo4j.json"
)
func main() {
_, err := util.CreateNeo4jDriver(neo4jPath)
if err != nil {
fmt.Println(err)
return
}
fmt.Println("Neo4j driver created successfully")
}メインプログラムを実行してデータベースの接続性を検証します:
go run main.goNeo4j driver created successfullyと出力されれば、データベースの接続性検証は成功です。
3. MCPサーバーの実装
GoのMCP SDKで最も有名なのはmark3labs/mcp-goです。これを使用します。
mark3labs/mcp-goのデモはhttps://github.com/mark3labs/mcp-goにあり、非常にシンプルです。ここでは直接使用します。
まずインストールします:
go get github.com/mark3labs/mcp-go次にmain.goに以下のコードを追加します:
// ... 既存のコード ...
var (
addr string = "localhost:8083"
)
func main() {
// ... 既存のコード ...
s := server.NewMCPServer(
"読み取り専用Neo4jサーバー",
"0.0.1",
server.WithToolCapabilities(true),
)
srv := server.NewSSEServer(s)
// executeReadOnlyCypherQueryツールのスキーマを定義
executeReadOnlyCypherQuery := mcp.NewTool("executeReadOnlyCypherQuery",
mcp.WithDescription("読み取り専用のCypherクエリを実行"),
mcp.WithString("cypher",
mcp.Required(),
mcp.Description("Cypherクエリ文、読み取り専用でなければなりません"),
),
)
// 実際の関数と宣言されたスキーマをバインド
s.AddTool(executeReadOnlyCypherQuery, func(ctx context.Context, request mcp.CallToolRequest) (*mcp.CallToolResult, error) {
args, ok := request.Params.Arguments.(map[string]interface{})
if !ok {
return mcp.NewToolResultText(""), fmt.Errorf("無効な引数の型")
}
cypher, ok := args["cypher"].(string)
if !ok {
return mcp.NewToolResultText(""), fmt.Errorf("cypher引数が文字列ではありません")
}
result, err := util.ExecuteReadOnlyCypherQuery(cypher)
fmt.Println(result)
if err != nil {
return mcp.NewToolResultText(""), err
}
return mcp.NewToolResultText(fmt.Sprintf("%v", result)), nil
})
// http://localhost:8083/sseでサービスを開始
fmt.Printf("サーバーがhttp://%s/sseで起動しました\n", addr)
srv.Start(addr)
}go run main.goを実行すると、以下の情報が表示されます:
Neo4j driver created successfully
サーバーがhttp://localhost:8083/sseで起動しましたこれで、MCPサーバーがローカルの8083ポートで起動しました。
4. OpenMCPを使用したデバッグ
4.1 ワークスペースにSSEデバッグプロジェクトを追加
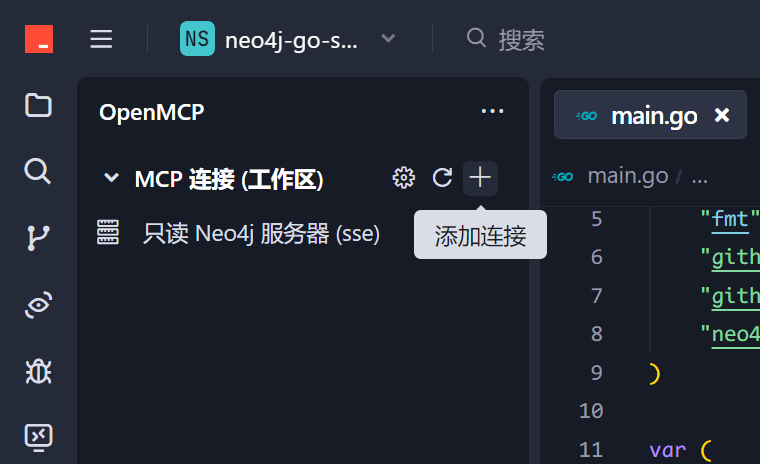
次に、OpenMCPを使用してデバッグを行います。まず、VSコードの左側にあるOpenMCPアイコンをクリックしてコントロールパネルに入ります。https://github.com/LSTM-Kirigaya/openmcp-tutorial/tree/main/neo4j-go-server からこのプロジェクトをダウンロードした場合、【MCP接続(ワークスペース)】に既に作成済みのデバッグプロジェクト【読み取り専用Neo4jサーバー】が表示されます。完全に自分でこのプロジェクトを作成した場合は、以下のボタンから接続を追加し、SSEを選択してhttp://localhost:8083/sseを入力し、OAuthは空のままにします。
4.2 ツールのテスト
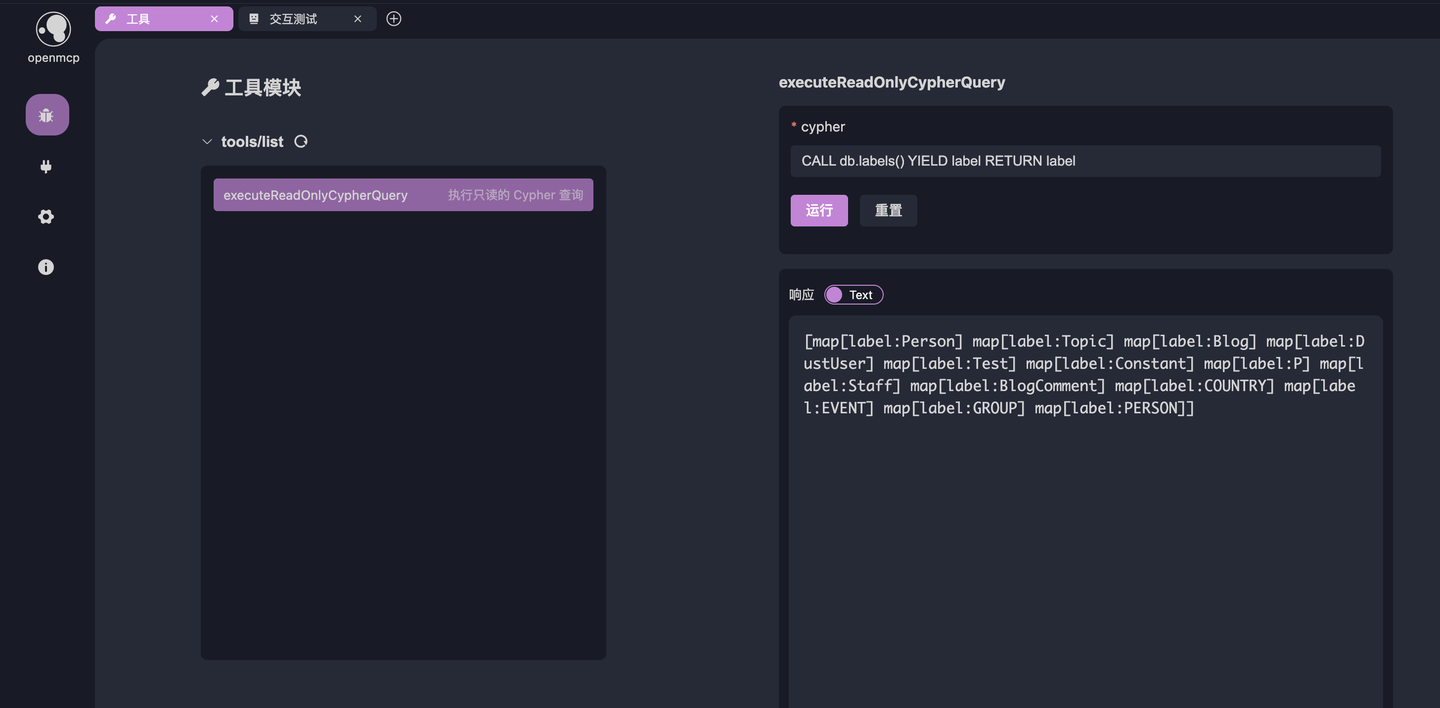
MCPサーバーを初めてデバッグする際に最初に行うべきことは、MCPツールを動作させることです。新しいタブを作成し、ツールを選択し、以下の図のツールをクリックして、CALL db.labels() YIELD label RETURN labelと入力します。この文はすべてのノードタイプをリストアップするために使用されます。以下の結果が出力されれば、現在のリンクは有効で問題ありません。
4.3 大規模言語モデルの機能範囲を理解し、プロンプトで知識をカプセル化する
それでは、面白いことをしてみましょう!次に、大規模言語モデルの能力範囲をテストします。なぜなら、Neo4jは特殊なデータベースであり、一般的な大規模言語モデルはその使用方法を知らないかもしれないからです。新しいタブを作成し、「インタラクティブテスト」をクリックし、まず簡単な質問をします:
最新の10件のコメントを見つけてください結果は以下の通りです:
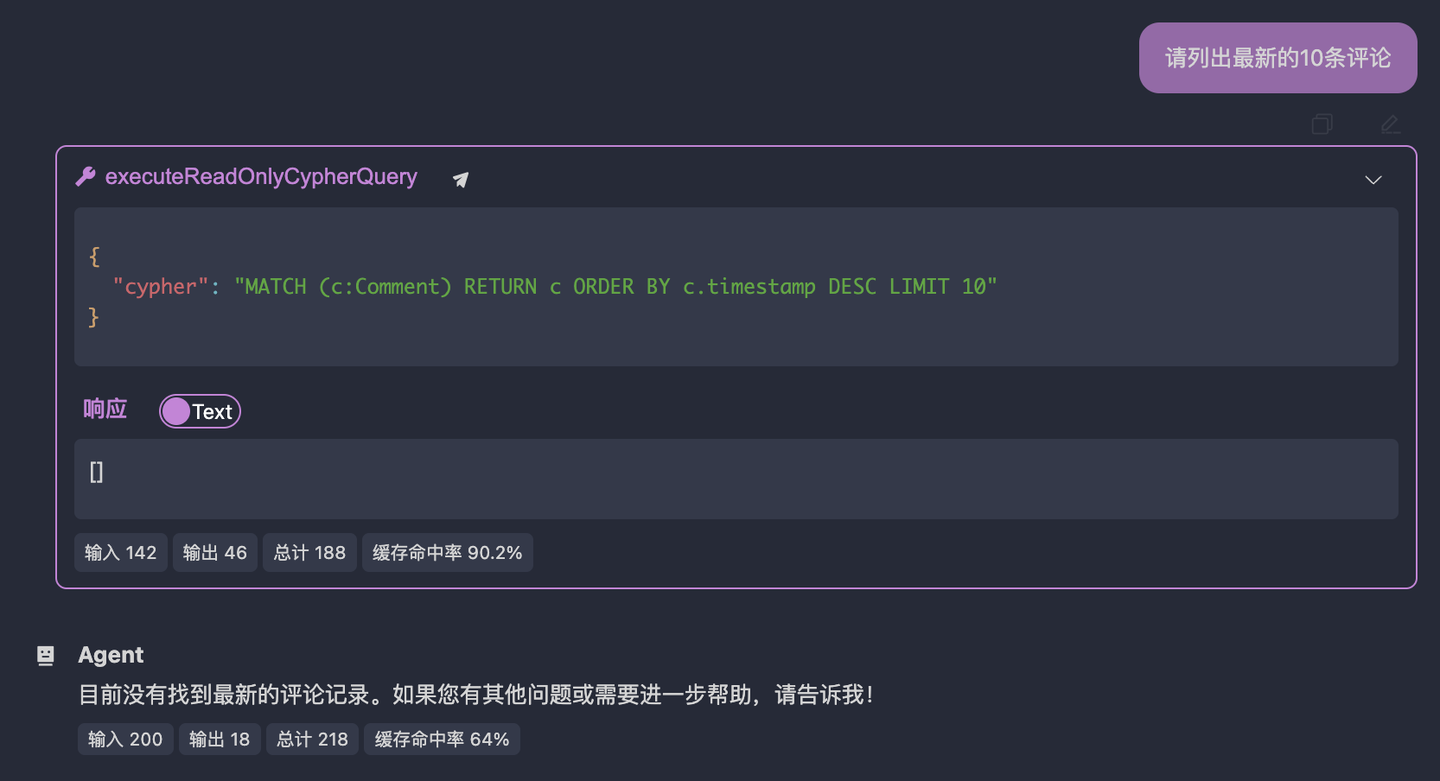
大規模言語モデルがクエリしたノードタイプが間違っていることがわかります。私が提供した例では、コメントを表すノードはBlogCommentであり、Commentではありません。つまり、大規模言語モデルはデータベースクエリの一般的な方法論を掌握していません。これが現在わかっているその能力範囲です。次に、私たちの経験と知識を段階的に注入します。うむ、システムプロンプトを通じて完了します。
4.4 大規模言語モデルにデータベースノードを見つける方法を教える
よく考えてみてください。エンジニアとして、私たちはどのようにしてコメントのノードがBlogCommentであることを知るのでしょうか?一般的に、現在のデータベースのすべてのノードタイプをリストアップし、命名から推測します。たとえば、このデータベースの場合、私はまず以下のようなCypherクエリを入力します:
CALL db.labels() YIELD label RETURN labelその出力は4.2の図にあります。英語が得意であれば、BlogCommentがおそらくブログコメントを表すノードであることがわかるでしょう。さて、この方法論をシステムプロンプトに注入し、この知識をカプセル化します。以下の図の下部のボタンをクリックして、【システムプロンプト】に入ります:
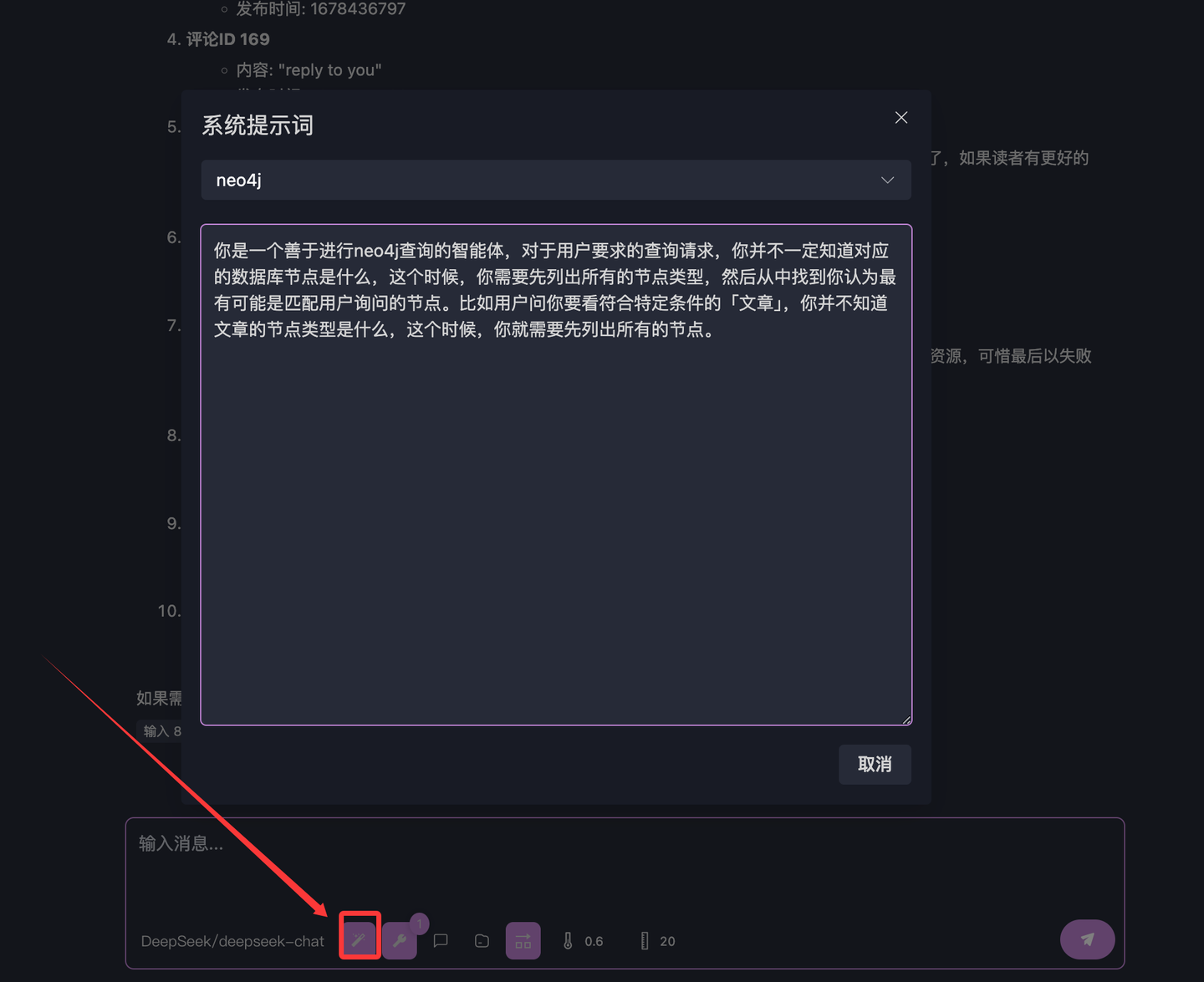
新しいプロンプト【neo4j】を作成し、入力します:
あなたはneo4jクエリが得意なインテリジェントエージェントです。ユーザーからのクエリリクエストに対して、対応するデータベースノードが何であるか必ずしも知っているわけではありません。その場合、まずすべてのノードタイプをリストアップし、その中からユーザーの質問に最も一致すると考えるノードを見つける必要があります。たとえば、ユーザーが特定の条件に合致する「記事」を見たいと尋ねた場合、記事ノードのタイプが何であるか知らないので、まずすべてのノードをリストアップする必要があります。保存をクリックし、【インタラクティブテスト】で先ほどの質問を繰り返します:
最新の10件のコメントを見つけてください大規模言語モデルの回答は以下の通りです:
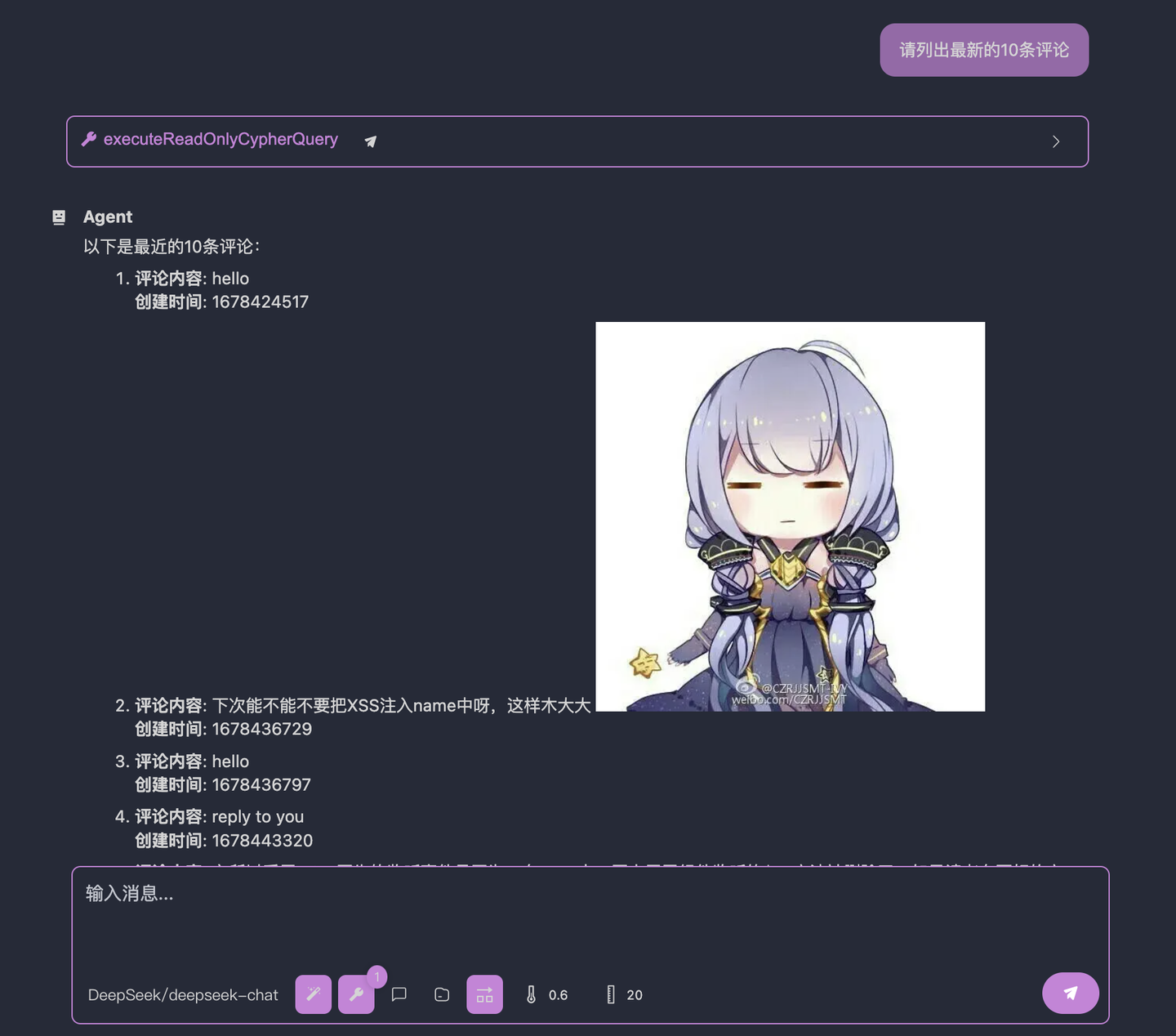
どうでしょう?ずっと良くなったのではないでしょうか?大規模言語モデルはBlogCommentノードを正しく見つけ、対応するデータを返しました。
しかし、まだ完全には正しくありません。なぜなら、私たちが要求したのは最新の10件のコメントですが、大規模言語モデルが返したのは実際には最も古い10件のコメントです。大規模言語モデルの呼び出しの詳細を開くと、大規模言語モデルはORDER BY comment.createdAtを使用して実装していることがわかります。しかし、問題は、私たちのデータベースでは、コメントが作成された時間を記録するフィールドはcreatedAtではなく、createdTimeであることです。これは、大規模言語モデルがノードのフィールドを知らないことを知らず、「幻覚」を起こし、適当なフィールドを入力したことを意味します。
大規模言語モデルは自分が知らないことを明示的に言うことはありません。錦恢研究生のOODに関する研究は、このことの本質的な理由を説明できます:EDL(Evidential Deep Learning)原理とコード実装。もしあなたの好奇心が数学の基礎力に匹敵するなら、この記事を試してみてください。とにかく、あなたが知っておくべきことは、大規模言語モデルが自分が知らないことに対して幻覚を起こすからこそ、私たちが経験を注入する操作の余地があるということです。
4.5 大規模言語モデルにデータベースノードのフィールドを見つける方法を教える
上記の試みを通じて、私たちは終点まであと少しであることを知りました。それは、大規模言語モデルに、私たちのデータベースでは、コメントが作成された時間を記録するフィールドはcreatedAtではなく、createdTimeであることを教えることです。
フィールドを識別する知識について、先ほどのシステムプロンプトを改良します:
あなたはneo4jクエリが得意なインテリジェントエージェントです。ユーザーからのクエリリクエストに対して、対応するデータベースノードが何であるか必ずしも知っているわけではありません。その場合、まずすべてのノードタイプをリストアップし、その中からユーザーの質問に最も一致すると考えるノードを見つける必要があります。たとえば、ユーザーが特定の条件に合致する「記事」を見たいと尋ねた場合、記事ノードのタイプが何であるか知らないので、まずすべてのノードをリストアップする必要があります。
より具体的なクエリの場合、まず1つまたは2つの事例をクエリして、現在のタイプにどのようなフィールドがあるかを確認する必要があります。たとえば、ユーザーが最新の記事を尋ねた場合、記事ノードのどのフィールドが「作成時間」を表すか知らないので、まず1つまたは2つの記事ノードをリストアップし、その中にどのようなフィールドがあるかを確認し、その後、最新の10件の記事をクエリする必要があります。結果は以下の通りです:
 LSTM-Kirigaya (锦恢)
LSTM-Kirigaya (锦恢)